ESPnet Speech Translation Demonstration¶
![]()
See also
ESPnet: https://github.com/espnet/espnet
ESPnet documentation: https://espnet.github.io/espnet/
TTS demo: https://colab.research.google.com/github/espnet/notebook/blob/master/tts_realtime_demo.ipynb
Author: Shigeki Karita
Install¶
It takes around 3 minutes. Please keep waiting for a while.
[1]:
# OS setup
!cat /etc/os-release
!apt-get install -qq bc tree sox
# espnet and moses setup
!git clone -q https://github.com/ShigekiKarita/espnet.git
!pip install -q torch==1.1
!cd espnet; git checkout c0466d9a356c1a33f671a546426d7bc33b5b17e8; pip install -q -e .
!cd espnet/tools/; make moses.done
# download pre-compiled warp-ctc and kaldi tools
!espnet/utils/download_from_google_drive.sh \
"https://drive.google.com/open?id=13Y4tSygc8WtqzvAVGK_vRV9GlV7TRC0w" espnet/tools tar.gz > /dev/null
# make dummy activate
!mkdir -p espnet/tools/venv/bin && touch espnet/tools/venv/bin/activate
!echo "setup done."
NAME="Ubuntu"
VERSION="18.04.3 LTS (Bionic Beaver)"
ID=ubuntu
ID_LIKE=debian
PRETTY_NAME="Ubuntu 18.04.3 LTS"
VERSION_ID="18.04"
HOME_URL="https://www.ubuntu.com/"
SUPPORT_URL="https://help.ubuntu.com/"
BUG_REPORT_URL="https://bugs.launchpad.net/ubuntu/"
PRIVACY_POLICY_URL="https://www.ubuntu.com/legal/terms-and-policies/privacy-policy"
VERSION_CODENAME=bionic
UBUNTU_CODENAME=bionic
Selecting previously unselected package libopencore-amrnb0:amd64.
(Reading database ... 145674 files and directories currently installed.)
Preparing to unpack .../0-libopencore-amrnb0_0.1.3-2.1_amd64.deb ...
Unpacking libopencore-amrnb0:amd64 (0.1.3-2.1) ...
Selecting previously unselected package libopencore-amrwb0:amd64.
Preparing to unpack .../1-libopencore-amrwb0_0.1.3-2.1_amd64.deb ...
Unpacking libopencore-amrwb0:amd64 (0.1.3-2.1) ...
Selecting previously unselected package libmagic-mgc.
Preparing to unpack .../2-libmagic-mgc_1%3a5.32-2ubuntu0.3_amd64.deb ...
Unpacking libmagic-mgc (1:5.32-2ubuntu0.3) ...
Selecting previously unselected package libmagic1:amd64.
Preparing to unpack .../3-libmagic1_1%3a5.32-2ubuntu0.3_amd64.deb ...
Unpacking libmagic1:amd64 (1:5.32-2ubuntu0.3) ...
Selecting previously unselected package bc.
Preparing to unpack .../4-bc_1.07.1-2_amd64.deb ...
Unpacking bc (1.07.1-2) ...
Selecting previously unselected package libsox3:amd64.
Preparing to unpack .../5-libsox3_14.4.2-3ubuntu0.18.04.1_amd64.deb ...
Unpacking libsox3:amd64 (14.4.2-3ubuntu0.18.04.1) ...
Selecting previously unselected package libsox-fmt-alsa:amd64.
Preparing to unpack .../6-libsox-fmt-alsa_14.4.2-3ubuntu0.18.04.1_amd64.deb ...
Unpacking libsox-fmt-alsa:amd64 (14.4.2-3ubuntu0.18.04.1) ...
Selecting previously unselected package libsox-fmt-base:amd64.
Preparing to unpack .../7-libsox-fmt-base_14.4.2-3ubuntu0.18.04.1_amd64.deb ...
Unpacking libsox-fmt-base:amd64 (14.4.2-3ubuntu0.18.04.1) ...
Selecting previously unselected package sox.
Preparing to unpack .../8-sox_14.4.2-3ubuntu0.18.04.1_amd64.deb ...
Unpacking sox (14.4.2-3ubuntu0.18.04.1) ...
Selecting previously unselected package tree.
Preparing to unpack .../9-tree_1.7.0-5_amd64.deb ...
Unpacking tree (1.7.0-5) ...
Setting up tree (1.7.0-5) ...
Setting up libmagic-mgc (1:5.32-2ubuntu0.3) ...
Setting up libmagic1:amd64 (1:5.32-2ubuntu0.3) ...
Setting up libopencore-amrnb0:amd64 (0.1.3-2.1) ...
Setting up bc (1.07.1-2) ...
Setting up libopencore-amrwb0:amd64 (0.1.3-2.1) ...
Setting up libsox3:amd64 (14.4.2-3ubuntu0.18.04.1) ...
Setting up libsox-fmt-base:amd64 (14.4.2-3ubuntu0.18.04.1) ...
Setting up libsox-fmt-alsa:amd64 (14.4.2-3ubuntu0.18.04.1) ...
Setting up sox (14.4.2-3ubuntu0.18.04.1) ...
Processing triggers for libc-bin (2.27-3ubuntu1) ...
Processing triggers for man-db (2.8.3-2ubuntu0.1) ...
Processing triggers for mime-support (3.60ubuntu1) ...
|████████████████████████████████| 676.9MB 15kB/s
ERROR: torchvision 0.4.2 has requirement torch==1.3.1, but you'll have torch 1.1.0 which is incompatible.
|████████████████████████████████| 890kB 3.5MB/s
|████████████████████████████████| 25.2MB 129kB/s
|████████████████████████████████| 1.6MB 40.6MB/s
|████████████████████████████████| 245kB 43.4MB/s
|████████████████████████████████| 174kB 62.9MB/s
|████████████████████████████████| 2.8MB 45.2MB/s
|████████████████████████████████| 204kB 48.5MB/s
|████████████████████████████████| 40kB 7.5MB/s
|████████████████████████████████| 276kB 55.7MB/s
|████████████████████████████████| 1.0MB 48.2MB/s
|████████████████████████████████| 419kB 55.3MB/s
|████████████████████████████████| 1.5MB 40.0MB/s
|████████████████████████████████| 1.7MB 42.1MB/s
|████████████████████████████████| 3.1MB 40.1MB/s
|████████████████████████████████| 81kB 12.7MB/s
|████████████████████████████████| 1.2MB 47.5MB/s
|████████████████████████████████| 92kB 14.1MB/s
|████████████████████████████████| 368kB 46.3MB/s
|████████████████████████████████| 184kB 57.0MB/s
|████████████████████████████████| 512kB 46.2MB/s
Building wheel for chainer (setup.py) ... done
Building wheel for librosa (setup.py) ... done
Building wheel for kaldiio (setup.py) ... done
Building wheel for configargparse (setup.py) ... done
Building wheel for PyYAML (setup.py) ... done
Building wheel for pysptk (setup.py) ... done
Building wheel for nltk (setup.py) ... done
Building wheel for nnmnkwii (setup.py) ... done
Building wheel for jaconv (setup.py) ... done
Building wheel for torch-complex (setup.py) ... done
Building wheel for pytorch-wpe (setup.py) ... done
Building wheel for simplejson (setup.py) ... done
Building wheel for bandmat (setup.py) ... done
Building wheel for distance (setup.py) ... done
ERROR: albumentations 0.1.12 has requirement imgaug<0.2.7,>=0.2.5, but you'll have imgaug 0.2.9 which is incompatible.
ERROR: tensorboardx 2.0 has requirement protobuf>=3.8.0, but you'll have protobuf 3.7.1 which is incompatible.
git clone https://github.com/moses-smt/mosesdecoder.git moses
Cloning into 'moses'...
remote: Enumerating objects: 219, done.
remote: Counting objects: 100% (219/219), done.
remote: Compressing objects: 100% (129/129), done.
remote: Total 147514 (delta 132), reused 135 (delta 84), pack-reused 147295
Receiving objects: 100% (147514/147514), 129.75 MiB | 22.22 MiB/s, done.
Resolving deltas: 100% (113966/113966), done.
touch moses.done
--2020-02-01 06:23:17-- https://drive.google.com/uc?export=download&id=13Y4tSygc8WtqzvAVGK_vRV9GlV7TRC0w
Resolving drive.google.com (drive.google.com)... 172.217.212.113, 172.217.212.100, 172.217.212.139, ...
Connecting to drive.google.com (drive.google.com)|172.217.212.113|:443... connected.
HTTP request sent, awaiting response... 200 OK
Length: unspecified [text/html]
Saving to: ‘espnet/tools/gX5bJU.tar.gz’
espnet/tools/gX5bJU [ <=> ] 3.22K --.-KB/s in 0s
2020-02-01 06:23:17 (50.9 MB/s) - ‘espnet/tools/gX5bJU.tar.gz’ saved [3295]
gzip: stdin: not in gzip format
tar: Child returned status 1
tar: Error is not recoverable: exiting now
% Total % Received % Xferd Average Speed Time Time Time Current
Dload Upload Total Spent Left Speed
100 3295 0 3295 0 0 30509 0 --:--:-- --:--:-- --:--:-- 30509
% Total % Received % Xferd Average Speed Time Time Time Current
Dload Upload Total Spent Left Speed
100 408 0 408 0 0 4387 0 --:--:-- --:--:-- --:--:-- 4387
0 0 0 0 0 0 0 0 --:--:-- --:--:-- --:--:-- 0
0 0 0 0 0 0 0 0 --:--:-- --:--:-- --:--:-- 0
100 662M 0 662M 0 0 62.8M 0 --:--:-- 0:00:10 --:--:-- 72.3M
setup done.
Spanish speech -> English text translation¶
This audio says “yo soy José.”
[ ]:
from IPython.display import display, Audio
display(Audio("/content/espnet/test_utils/st_test.wav", rate=16000))
Let’s translate this into English text by our pretrained Transformer ST model trained on the Fisher-CALLHOME Spanish dataset.
[2]:
# move on the recipe directory
import os
os.chdir("/content/espnet/egs/fisher_callhome_spanish/st1")
!../../../utils/translate_wav.sh --models fisher_callhome_spanish.transformer.v1.es-en ../../../test_utils/st_test.wav | tee /content/translated.txt
--2020-02-01 06:27:27-- https://drive.google.com/uc?export=download&id=1hawp5ZLw4_SIHIT3edglxbKIIkPVe8n3
Resolving drive.google.com (drive.google.com)... 108.177.112.101, 108.177.112.138, 108.177.112.113, ...
Connecting to drive.google.com (drive.google.com)|108.177.112.101|:443... connected.
HTTP request sent, awaiting response... 200 OK
Length: unspecified [text/html]
Saving to: 'decode/download/fisher_callhome_spanish.transformer.v1.es-en/ggCWsF..tar.gz'
decode/do [<=> ] 0 --.-KB/sdecode/download/fis [ <=> ] 3.26K –.-KB/s in 0s
2020-02-01 06:27:27 (71.2 MB/s) - ‘decode/download/fisher_callhome_spanish.transformer.v1.es-en/ggCWsF..tar.gz’ saved [3338]
gzip: stdin: not in gzip format tar: Child returned status 1 tar: Error is not recoverable: exiting now
- % Total % Received % Xferd Average Speed Time Time Time Current
Dload Upload Total Spent Left Speed
0 0 0 0 0 0 0 0 –:–:– –:–:– –:–:– 0
- 100 3338 0 3338 0 0 16944 0 –:–:– –:–:– –:–:– 16944
- % Total % Received % Xferd Average Speed Time Time Time Current
Dload Upload Total Spent Left Speed
0 0 0 0 0 0 0 0 –:–:– –:–:– –:–:– 0
100 408 0 408 0 0 4039 0 –:–:– –:–:– –:–:– 4039
- 0 0 0 0 0 0 0 0 –:–:– –:–:– –:–:– 0
0 0 0 0 0 0 0 0 –:–:– –:–:– –:–:– 0
100 97.8M 0 97.8M 0 0 82.9M 0 –:–:– 0:00:01 –:–:– 174M conf/tuning/train_pytorch_transformer_bpe_short_long.yaml conf/tuning/decode_pytorch_transformer_bpe.yaml conf/specaug.yaml data/train_sp.en/cmvn.ark exp/train_sp.en_lc.rm_pytorch_train_pytorch_transformer_bpe_short_long_bpe1000_specaug_asrtrans_mttrans/results/model.val5.avg.best exp/train_sp.en_lc.rm_pytorch_train_pytorch_transformer_bpe_short_long_bpe1000_specaug_asrtrans_mttrans/results/model.json Sucessfully downloaded zip file from https://drive.google.com/open?id=1hawp5ZLw4_SIHIT3edglxbKIIkPVe8n3 stage 0: Data preparation stage 1: Feature Generation steps/make_fbank_pitch.sh –cmd run.pl –nj 1 –write_utt2num_frames true decode/st_test/data decode/st_test/log decode/st_test/fbank utils/validate_data_dir.sh: WARNING: you have only one speaker. This probably a bad idea.
Search for the word ‘bold’ in http://kaldi-asr.org/doc/data_prep.html for more information.
utils/validate_data_dir.sh: Successfully validated data-directory decode/st_test/data steps/make_fbank_pitch.sh: [info]: no segments file exists: assuming wav.scp indexed by utterance. steps/make_fbank_pitch.sh: Succeeded creating filterbank and pitch features for data /content/espnet/egs/fisher_callhome_spanish/st1/../../../utils/dump.sh –cmd run.pl –nj 1 –do_delta false decode/st_test/data/feats.scp decode/download/fisher_callhome_spanish.transformer.v1.es-en/data/train_sp.en/cmvn.ark decode/st_test/log decode/st_test/dump stage 2: Json Data Preparation /content/espnet/egs/fisher_callhome_spanish/st1/../../../utils/data2json.sh –feat decode/st_test/dump/feats.scp decode/st_test/data decode/st_test/dict /content/espnet/egs/fisher_callhome_spanish/st1/../../../utils/feat_to_shape.sh –cmd run.pl –nj 1 –filetype –preprocess-conf –verbose 0 decode/st_test/dump/feats.scp decode/st_test/data/tmp-1PxS1/input_1/shape.scp sym2int.pl: replacing X with 1 ** Replaced 1 instances of OOVs with 1 stage 3: Decoding
Detokenizer Version $Revision: 4134 $ Language: en Translated text: yes i’m jose
Finished </pre>
decode/download/fis [ <=> ] 3.26K –.-KB/s in 0s
2020-02-01 06:27:27 (71.2 MB/s) - ‘decode/download/fisher_callhome_spanish.transformer.v1.es-en/ggCWsF..tar.gz’ saved [3338]
gzip: stdin: not in gzip format tar: Child returned status 1 tar: Error is not recoverable: exiting now
- % Total % Received % Xferd Average Speed Time Time Time Current
Dload Upload Total Spent Left Speed
0 0 0 0 0 0 0 0 –:–:– –:–:– –:–:– 0
- 100 3338 0 3338 0 0 16944 0 –:–:– –:–:– –:–:– 16944
- % Total % Received % Xferd Average Speed Time Time Time Current
Dload Upload Total Spent Left Speed
0 0 0 0 0 0 0 0 –:–:– –:–:– –:–:– 0
100 408 0 408 0 0 4039 0 –:–:– –:–:– –:–:– 4039
- 0 0 0 0 0 0 0 0 –:–:– –:–:– –:–:– 0
0 0 0 0 0 0 0 0 –:–:– –:–:– –:–:– 0
100 97.8M 0 97.8M 0 0 82.9M 0 –:–:– 0:00:01 –:–:– 174M conf/tuning/train_pytorch_transformer_bpe_short_long.yaml conf/tuning/decode_pytorch_transformer_bpe.yaml conf/specaug.yaml data/train_sp.en/cmvn.ark exp/train_sp.en_lc.rm_pytorch_train_pytorch_transformer_bpe_short_long_bpe1000_specaug_asrtrans_mttrans/results/model.val5.avg.best exp/train_sp.en_lc.rm_pytorch_train_pytorch_transformer_bpe_short_long_bpe1000_specaug_asrtrans_mttrans/results/model.json Sucessfully downloaded zip file from https://drive.google.com/open?id=1hawp5ZLw4_SIHIT3edglxbKIIkPVe8n3 stage 0: Data preparation stage 1: Feature Generation steps/make_fbank_pitch.sh –cmd run.pl –nj 1 –write_utt2num_frames true decode/st_test/data decode/st_test/log decode/st_test/fbank utils/validate_data_dir.sh: WARNING: you have only one speaker. This probably a bad idea.
Search for the word ‘bold’ in http://kaldi-asr.org/doc/data_prep.html for more information.
utils/validate_data_dir.sh: Successfully validated data-directory decode/st_test/data steps/make_fbank_pitch.sh: [info]: no segments file exists: assuming wav.scp indexed by utterance. steps/make_fbank_pitch.sh: Succeeded creating filterbank and pitch features for data /content/espnet/egs/fisher_callhome_spanish/st1/../../../utils/dump.sh –cmd run.pl –nj 1 –do_delta false decode/st_test/data/feats.scp decode/download/fisher_callhome_spanish.transformer.v1.es-en/data/train_sp.en/cmvn.ark decode/st_test/log decode/st_test/dump stage 2: Json Data Preparation /content/espnet/egs/fisher_callhome_spanish/st1/../../../utils/data2json.sh –feat decode/st_test/dump/feats.scp decode/st_test/data decode/st_test/dict /content/espnet/egs/fisher_callhome_spanish/st1/../../../utils/feat_to_shape.sh –cmd run.pl –nj 1 –filetype –preprocess-conf –verbose 0 decode/st_test/dump/feats.scp decode/st_test/data/tmp-1PxS1/input_1/shape.scp sym2int.pl: replacing X with 1 ** Replaced 1 instances of OOVs with 1 stage 3: Decoding
Detokenizer Version $Revision: 4134 $ Language: en Translated text: yes i’m jose
Finished end{sphinxVerbatim}
decode/download/fis [ <=> ] 3.26K –.-KB/s in 0s
2020-02-01 06:27:27 (71.2 MB/s) - ‘decode/download/fisher_callhome_spanish.transformer.v1.es-en/ggCWsF..tar.gz’ saved [3338]
gzip: stdin: not in gzip format tar: Child returned status 1 tar: Error is not recoverable: exiting now
- % Total % Received % Xferd Average Speed Time Time Time Current
Dload Upload Total Spent Left Speed
0 0 0 0 0 0 0 0 –:–:– –:–:– –:–:– 0
- 100 3338 0 3338 0 0 16944 0 –:–:– –:–:– –:–:– 16944
- % Total % Received % Xferd Average Speed Time Time Time Current
Dload Upload Total Spent Left Speed
0 0 0 0 0 0 0 0 –:–:– –:–:– –:–:– 0
100 408 0 408 0 0 4039 0 –:–:– –:–:– –:–:– 4039
- 0 0 0 0 0 0 0 0 –:–:– –:–:– –:–:– 0
0 0 0 0 0 0 0 0 –:–:– –:–:– –:–:– 0
100 97.8M 0 97.8M 0 0 82.9M 0 –:–:– 0:00:01 –:–:– 174M conf/tuning/train_pytorch_transformer_bpe_short_long.yaml conf/tuning/decode_pytorch_transformer_bpe.yaml conf/specaug.yaml data/train_sp.en/cmvn.ark exp/train_sp.en_lc.rm_pytorch_train_pytorch_transformer_bpe_short_long_bpe1000_specaug_asrtrans_mttrans/results/model.val5.avg.best exp/train_sp.en_lc.rm_pytorch_train_pytorch_transformer_bpe_short_long_bpe1000_specaug_asrtrans_mttrans/results/model.json Sucessfully downloaded zip file from https://drive.google.com/open?id=1hawp5ZLw4_SIHIT3edglxbKIIkPVe8n3 stage 0: Data preparation stage 1: Feature Generation steps/make_fbank_pitch.sh –cmd run.pl –nj 1 –write_utt2num_frames true decode/st_test/data decode/st_test/log decode/st_test/fbank utils/validate_data_dir.sh: WARNING: you have only one speaker. This probably a bad idea.
Search for the word ‘bold’ in http://kaldi-asr.org/doc/data_prep.html for more information.
utils/validate_data_dir.sh: Successfully validated data-directory decode/st_test/data steps/make_fbank_pitch.sh: [info]: no segments file exists: assuming wav.scp indexed by utterance. steps/make_fbank_pitch.sh: Succeeded creating filterbank and pitch features for data /content/espnet/egs/fisher_callhome_spanish/st1/../../../utils/dump.sh –cmd run.pl –nj 1 –do_delta false decode/st_test/data/feats.scp decode/download/fisher_callhome_spanish.transformer.v1.es-en/data/train_sp.en/cmvn.ark decode/st_test/log decode/st_test/dump stage 2: Json Data Preparation /content/espnet/egs/fisher_callhome_spanish/st1/../../../utils/data2json.sh –feat decode/st_test/dump/feats.scp decode/st_test/data decode/st_test/dict /content/espnet/egs/fisher_callhome_spanish/st1/../../../utils/feat_to_shape.sh –cmd run.pl –nj 1 –filetype –preprocess-conf –verbose 0 decode/st_test/dump/feats.scp decode/st_test/data/tmp-1PxS1/input_1/shape.scp sym2int.pl: replacing X with 1 ** Replaced 1 instances of OOVs with 1 stage 3: Decoding
Detokenizer Version $Revision: 4134 $ Language: en Translated text: yes i’m jose
Finished
As seen above, we successfully obtained the result: “Translated text: yes i’m jose”!
English translated text-to-speech synthesis¶
Now let’s generate an English speech from the translated text using a pretrained ESPnet-TTS model.
[ ]:
!sed -n 's/Translated text://p' /content/translated.txt | tr '[:lower:]' '[:upper:]' | tee /content/translated_sed.txt
!../../../utils/synth_wav.sh /content/translated_sed.txt
YES I'M JOSE
stage 0: Data preparation
/content/espnet/egs/ljspeech/tts1/../../../utils/data2json.sh --trans_type char decode/translated_sed/data decode/download/ljspeech.transformer.v1/data/lang_1char/train_no_dev_units.txt
stage 2: Decoding
stage 3: Synthesis with Griffin-Lim
apply-cmvn --norm-vars=true --reverse=true decode/download/ljspeech.transformer.v1/data/train_no_dev/cmvn.ark scp:decode/translated_sed/outputs/feats.scp ark,scp:decode/translated_sed/outputs_denorm/feats.ark,decode/translated_sed/outputs_denorm/feats.scp
LOG (apply-cmvn[5.5.428~1-29b3]:main():apply-cmvn.cc:159) Applied cepstral mean and variance normalization to 1 utterances, errors on 0
/content/espnet/egs/ljspeech/tts1/../../../utils/convert_fbank.sh --nj 1 --cmd run.pl --fs 22050 --fmax --fmin --n_fft 1024 --n_shift 256 --win_length --n_mels 80 --iters 64 decode/translated_sed/outputs_denorm decode/translated_sed/log decode/translated_sed/wav
Succeeded creating wav for outputs_denorm
Synthesized wav: decode/translated_sed/wav/translated_sed.wav
Finished
stage 4: Synthesis with Neural Vocoder
2020-01-31 05:38:17,532 (decode:95) INFO: The feature loaded from decode/translated_sed/outputs/feats.scp.
2020-01-31 05:38:21,674 (decode:110) INFO: Loaded model parameters from decode/download/ljspeech.parallel_wavegan.v1/ljspeech.parallel_wavegan.v1/checkpoint-400000steps.pkl.
[decode]: 0it [00:00, ?it/s]THCudaCheck FAIL file=/pytorch/aten/src/THC/THCGeneral.cpp line=383 error=11 : invalid argument
[decode]: 1it [00:00, 13.43it/s, RTF=0.0581]
2020-01-31 05:38:21,750 (decode:134) INFO: Finished generation of 1 utterances (RTF = 0.058).
Synthesized wav: decode/translated_sed/wav_wnv/translated_sed.wav
Finished
[ ]:
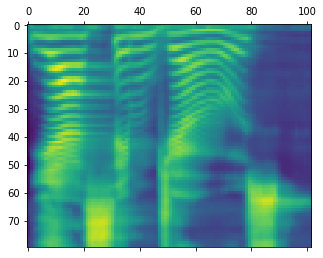
import matplotlib.pyplot as plt
import kaldiio
fbank = next(iter(kaldiio.load_scp("decode/translated_sed/outputs/feats.scp").values()))
plt.matshow(fbank.T)
<matplotlib.image.AxesImage at 0x7f7b3ac12e48>
[ ]:
from IPython.display import display, Audio
display(Audio("decode/translated_sed/wav_wnv/translated_sed_gen.wav"))
Successfully, it says “Yes I’m Jose”! For more TTS demo, visit https://colab.research.google.com/github/espnet/notebook/blob/master/tts_realtime_demo.ipynb
Check decoding log¶
After the translation, you will find <decode_dir>/<wav name>/result.json for details;
[ ]:
!cat decode/st_test/result.json
{
"utts": {
"st_test": {
"output": [
{
"name": "target1[1]",
"rec_text": "▁yes▁i▁'m▁jose<eos>",
"rec_token": "▁yes ▁i ▁ ' m ▁j ose <eos>",
"rec_tokenid": "991 638 371 2 219 656 256 999",
"score": 1.0691701889038088,
"shape": [
1,
3
],
"text": "X",
"token": "X",
"tokenid": "1"
}
],
"utt2spk": "X"
}
}
}
and <decode_dir>/<wav name>/log/decode.log for runtime log;
[25]:
!cat decode/st_test/log/decode.log
# st_trans.py --config decode/download/fisher_callhome_spanish.transformer.v1.es-en/conf/tuning/decode_pytorch_transformer_bpe.yaml --ngpu 0 --backend pytorch --debugmode 1 --verbose 1 --trans-json decode/st_test/dump/data.json --result-label decode/st_test/result.json --model decode/download/fisher_callhome_spanish.transformer.v1.es-en/exp/train_sp.en_lc.rm_pytorch_train_pytorch_transformer_bpe_short_long_bpe1000_specaug_asrtrans_mttrans/results/model.val5.avg.best --api v2
# Started at Sat Feb 1 06:27:34 UTC 2020
#
2020-02-01 06:27:34,638 (st_trans:126) INFO: python path = /env/python
2020-02-01 06:27:34,640 (st_trans:131) INFO: set random seed = 1
2020-02-01 06:27:34,640 (st_trans:139) INFO: backend = pytorch
2020-02-01 06:27:40,269 (deterministic_utils:24) INFO: torch type check is disabled
2020-02-01 06:27:40,269 (asr_utils:439) INFO: reading a config file from decode/download/fisher_callhome_spanish.transformer.v1.es-en/exp/train_sp.en_lc.rm_pytorch_train_pytorch_transformer_bpe_short_long_bpe1000_specaug_asrtrans_mttrans/results/model.json
2020-02-01 06:27:40,270 (asr_init:128) WARNING: reading model parameters from decode/download/fisher_callhome_spanish.transformer.v1.es-en/exp/train_sp.en_lc.rm_pytorch_train_pytorch_transformer_bpe_short_long_bpe1000_specaug_asrtrans_mttrans/results/model.val5.avg.best
/usr/local/lib/python3.6/dist-packages/torch/nn/_reduction.py:46: UserWarning: size_average and reduce args will be deprecated, please use reduction='none' instead.
warnings.warn(warning.format(ret))
2020-02-01 06:27:41,093 (io_utils:59) WARNING: [Experimental feature] Some preprocessing will be done for the mini-batch creation using Transformation(
0: TimeWarp(max_time_warp=5, inplace=True, mode=PIL)
1: FreqMask(F=30, n_mask=2, replace_with_zero=False, inplace=True)
2: TimeMask(T=40, n_mask=2, replace_with_zero=False, inplace=True))
2020-02-01 06:27:41,093 (st:449) INFO: (1/1) decoding st_test
2020-02-01 06:27:41,094 (e2e_st_transformer:338) INFO: <sos> index: 999
2020-02-01 06:27:41,095 (e2e_st_transformer:339) INFO: <sos> mark: <eos>
2020-02-01 06:27:41,175 (e2e_st_transformer:344) INFO: input lengths: 48
2020-02-01 06:27:41,175 (e2e_st_transformer:357) INFO: max output length: 14
2020-02-01 06:27:41,175 (e2e_st_transformer:358) INFO: min output length: 0
2020-02-01 06:27:42,643 (e2e_st_transformer:421) INFO: adding <eos> in the last postion in the loop
2020-02-01 06:27:42,644 (e2e_st_transformer:451) INFO: no hypothesis. Finish decoding.
2020-02-01 06:27:42,645 (e2e_st_transformer:472) INFO: total log probability: 1.0691701889038088
2020-02-01 06:27:42,645 (e2e_st_transformer:473) INFO: normalized log probability: 0.11879668765597876
2020-02-01 06:27:42,645 (asr_utils:626) INFO: groundtruth: X
2020-02-01 06:27:42,645 (asr_utils:627) INFO: prediction : ▁yes▁i▁'m▁jose<eos>
# Accounting: time=9 threads=1
# Ended (code 0) at Sat Feb 1 06:27:43 UTC 2020, elapsed time 9 seconds
Let’s calculate real-time factor (RTF) of the ST decoding from the decode.log
[54]:
from dateutil import parser
from subprocess import PIPE, run
# calc input duration (seconds)
input_sec = float(run(["soxi", "-D", "/content/espnet/test_utils/st_test.wav"], stdout=PIPE).stdout)
# calc NN decoding time
with open("decode/st_test/log/decode.log", "r") as f:
times = [parser.parse(x.split("(")[0]) for x in f if "e2e_st_transformer" in x]
decode_sec = (times[-1] - times[0]).total_seconds()
# get real-time factor (RTF)
print("Input duration:\t", input_sec, "sec")
print("NN decoding:\t", decode_sec, "sec")
print("Real-time factor:\t", decode_sec / input_sec)
Input duration: 2.0 sec
NN decoding: 1.551 sec
Real-time factor: 0.7755
As you can see above, ESPnet-ST can translate speech faster than the input (it should be RTF < 1.0).
Training ST models from scratch¶
We provide Kaldi-style recipes for ST as well as ASR and TTS as all-in-one bash script run.sh:
[ ]:
!cd /content/espnet/egs/must_c/st1/ && ./run.sh --must-c /content
stage -1: Data Download
local/download_and_untar.sh: downloading data from https://drive.google.com/open?id=1Mf2il_VelDIJMSio0bq7I8M9fSs-X4Ie. This may take some time, please be patient.
--2020-01-31 06:29:10-- https://drive.google.com/uc?export=download&id=1Mf2il_VelDIJMSio0bq7I8M9fSs-X4Ie
Resolving drive.google.com (drive.google.com)... 172.217.214.102, 172.217.214.138, 172.217.214.100, ...
Connecting to drive.google.com (drive.google.com)|172.217.214.102|:443... connected.
HTTP request sent, awaiting response... 200 OK
Length: unspecified [text/html]
Saving to: '/content/WGgpBx.tar.gz'/content/WGgpBx.tar [<=> ] 0 –.-KB/s /content/WGgpBx.tar [ <=> ] 3.18K –.-KB/s in 0s
2020-01-31 06:29:11 (38.8 MB/s) - ‘/content/WGgpBx.tar.gz’ saved [3259]
gzip: stdin: not in gzip format tar: Child returned status 1 tar: Error is not recoverable: exiting now
- % Total % Received % Xferd Average Speed Time Time Time Current
Dload Upload Total Spent Left Speed
0 0 0 0 0 0 0 0 –:–:– –:–:– –:–:– 0
- 100 3259 0 3259 0 0 16886 0 –:–:– –:–:– –:–:– 16886
- % Total % Received % Xferd Average Speed Time Time Time Current
Dload Upload Total Spent Left Speed
100 388 0 388 0 0 2000 0 –:–:– –:–:– –:–:– 1989 100 16.7G 0 16.7G 0 0 40.9M 0 –:–:– 0:06:59 –:–:– 40.4M^C </pre>
/content/WGgpBx.tar [<=> ] 0 –.-KB/s /content/WGgpBx.tar [ <=> ] 3.18K –.-KB/s in 0s
2020-01-31 06:29:11 (38.8 MB/s) - ‘/content/WGgpBx.tar.gz’ saved [3259]
gzip: stdin: not in gzip format tar: Child returned status 1 tar: Error is not recoverable: exiting now
- % Total % Received % Xferd Average Speed Time Time Time Current
Dload Upload Total Spent Left Speed
0 0 0 0 0 0 0 0 –:–:– –:–:– –:–:– 0
- 100 3259 0 3259 0 0 16886 0 –:–:– –:–:– –:–:– 16886
- % Total % Received % Xferd Average Speed Time Time Time Current
Dload Upload Total Spent Left Speed
100 388 0 388 0 0 2000 0 –:–:– –:–:– –:–:– 1989 100 16.7G 0 16.7G 0 0 40.9M 0 –:–:– 0:06:59 –:–:– 40.4M^{}C end{sphinxVerbatim}
/content/WGgpBx.tar [<=> ] 0 –.-KB/s /content/WGgpBx.tar [ <=> ] 3.18K –.-KB/s in 0s
2020-01-31 06:29:11 (38.8 MB/s) - ‘/content/WGgpBx.tar.gz’ saved [3259]
gzip: stdin: not in gzip format tar: Child returned status 1 tar: Error is not recoverable: exiting now
- % Total % Received % Xferd Average Speed Time Time Time Current
Dload Upload Total Spent Left Speed
0 0 0 0 0 0 0 0 –:–:– –:–:– –:–:– 0
- 100 3259 0 3259 0 0 16886 0 –:–:– –:–:– –:–:– 16886
- % Total % Received % Xferd Average Speed Time Time Time Current
Dload Upload Total Spent Left Speed
100 388 0 388 0 0 2000 0 –:–:– –:–:– –:–:– 1989 100 16.7G 0 16.7G 0 0 40.9M 0 –:–:– 0:06:59 –:–:– 40.4M^C
However, it takes too much time to finish downloading the dataset. So we cancel the cell above.
Details of ESPnet tools¶
[ ]:
!../../../utils/translate_wav.sh --help
Usage:
../../../utils/translate_wav.sh [options] <wav_file>
Options:
--ngpu <ngpu> # Number of GPUs (Default: 0)
--decode_dir <directory_name> # Name of directory to store decoding temporary data
--models <model_name> # Model name (e.g. tedlium2.transformer.v1)
--cmvn <path> # Location of cmvn.ark
--trans_model <path> # Location of E2E model
--decode_config <path> # Location of configuration file
--api <api_version> # API version (v1 or v2)
Example:
# Record audio from microphone input as example.wav
rec -c 1 -r 16000 example.wav trim 0 5
# Decode using model name
../../../utils/translate_wav.sh --models must_c.transformer.v1.en-fr example.wav
# Decode using model file
../../../utils/translate_wav.sh --cmvn cmvn.ark --trans_model model.acc.best --decode_config conf/decode.yaml example.wav
# Decode with GPU (require batchsize > 0 in configuration file)
../../../utils/translate_wav.sh --ngpu 1 example.wav
Available models:
- must_c.transformer.v1.en-fr
- fisher_callhome_spanish.transformer.v1.es-en
[ ]:
!../../../utils/synth_wav.sh --help
Usage:
$ ../../../utils/synth_wav.sh <text>
Example:
# make text file and then generate it
echo "This is a demonstration of text to speech." > example.txt
../../../utils/synth_wav.sh example.txt
# you can specify the pretrained models
../../../utils/synth_wav.sh --models ljspeech.transformer.v3 example.txt
# also you can specify vocoder model
../../../utils/synth_wav.sh --vocoder_models ljspeech.wavenet.mol.v2 --stop_stage 4 example.txt
Available models:
- ljspeech.tacotron2.v1
- ljspeech.tacotron2.v2
- ljspeech.tacotron2.v3
- ljspeech.transformer.v1
- ljspeech.transformer.v2
- ljspeech.transformer.v3
- ljspeech.fastspeech.v1
- ljspeech.fastspeech.v2
- ljspeech.fastspeech.v3
- libritts.tacotron2.v1
- libritts.transformer.v1
- jsut.transformer.v1
- jsut.tacotron2.v1
- csmsc.transformer.v1
- csmsc.fastspeech.v3
Available vocoder models:
- ljspeech.wavenet.softmax.ns.v1
- ljspeech.wavenet.mol.v1
- ljspeech.parallel_wavegan.v1
- libritts.wavenet.mol.v1
- jsut.wavenet.mol.v1
- jsut.parallel_wavegan.v1
- csmsc.wavenet.mol.v1
- csmsc.parallel_wavegan.v1
[ ]: